






Label Words are Anchors An Information Flow Perspective for Understanding In-Context Learning深度解析
深入理解Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
abs
只测试了GPT模型
- 探究了ICL(in context learning)如何学习上下文的机制
- 提出”Information Flow with Labels as Anchors”假说
- 发现靠前的layer主要做aggregation来聚合信息, 靠后的layer不那么aggregation, 更多的提取功能
- Figure 1, Figure 2
- 提出anchor re-weighting方法和压缩方法来加速推理
- 1.8x推理提速
background:什么是ICL
我对ICL的理解: 提问前举例子。不用更新模型权重就能让模型学到东西。和few-shot的区别在于few-shot的举例是在finetune阶段的, 即是会更新模型权重的举例说明。
假设的证明
在实际应用上完全不需要复杂的score计算,这得益于ICL的机制。
假设:
- 浅层layer负责聚合
- 深层layer负责提取
显著性得分Saliency Scores
attn_map或者说attn score或者说attn weight与loss对attn的导(利用torch的自动求导机制)的累加
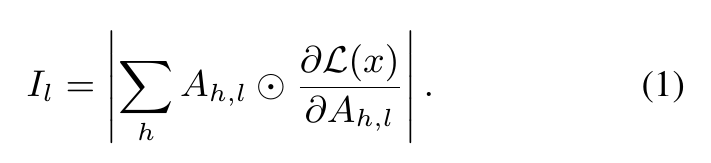
代码实现
- 为了能对attn求导,则让attn乘上一个占位参数,反向时参数就会自动求导并和attn相乘
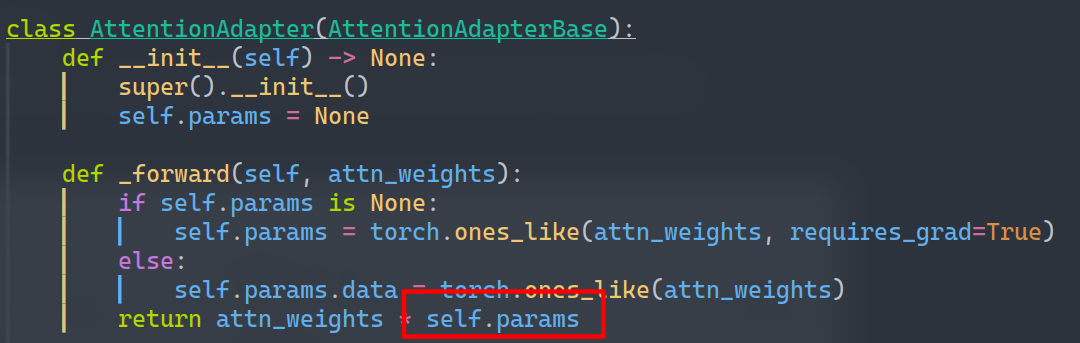
- 因为上图在自动求导(反向)完成后就会自动形成Sigma右边的结构,所以使用时只需要sum和abs即可
这是显著性的计算, 但在实际应用中是用不到显著性计算的,直接利用ICL中的lable id提取即可。
验证浅层layer的影响
基于信息流的验证
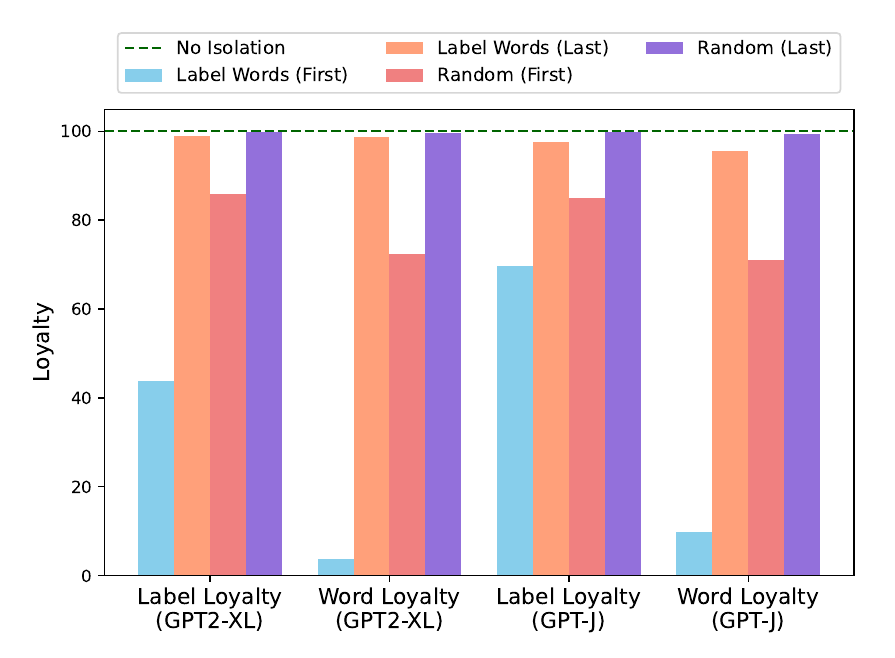
- 在浅层block掉label位置的信息聚合流(attn weight)影响大, 在深层block掉信息聚合流(attn weight)影响小, 说明只有浅层有聚合作用, 深层几乎没有影响
- 随机block的影响不及对lable的精确block,说明确实lable的聚合作用比较重要
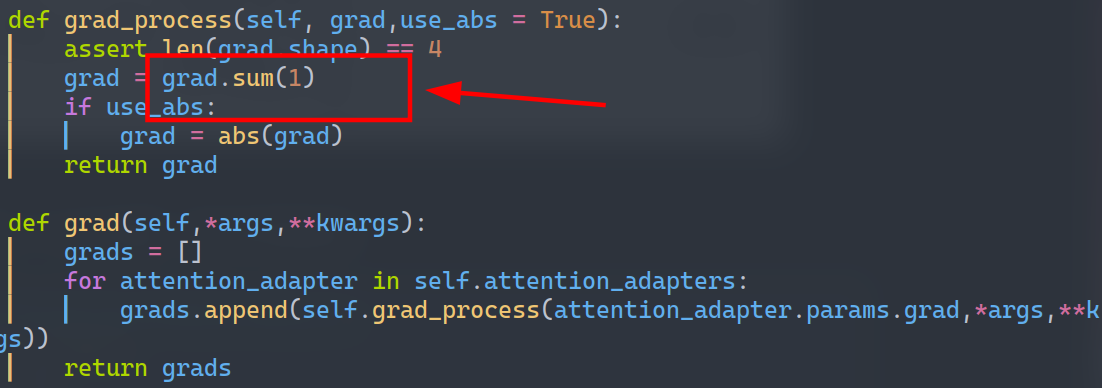
阻塞信息流的代码实现:修改attention weight(attn score),把label对上文的注意力全部mask掉
1 | def _forward(self, attn_weights): |
基于显著性得分的验证
代码实现
- 根据上一节的方法知道显著性的计算方法后这节对比各个阶段显著性的主导地位class_pos表示lable在输入序列的位置

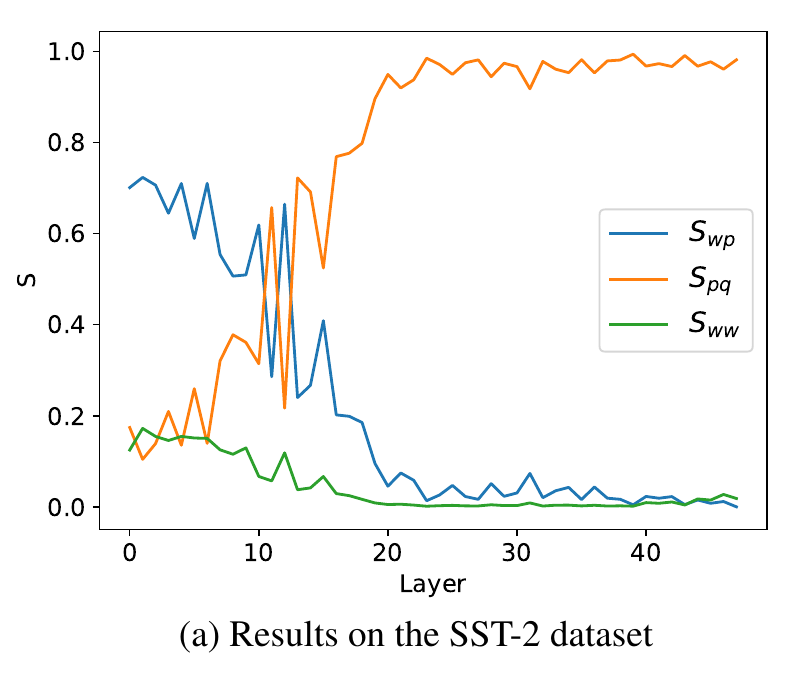
- proportion1,2,3分别是S_wp(信息流向label), S_pq(label流向目标预测token), S_ww(其他信息流)

- 可见浅层时S_wp占主导(信息流向label), 深层时S_pq占主导(目标预测从lable中提取), 其他情况(S_ww)影响不大
验证深层layer的影响
思路: 模型的最终预测结果应该和lable有很强的相关性(a strong correlation between the attention distributions on the label words of the target position and the model’s final prediction)
所以引入了AUCROC得分来衡量模型输出和lable的attention的相关性。并且为了为了验证l层累积的效果还引入了Rl(eq 5), 并设置了一个0.5的threshold
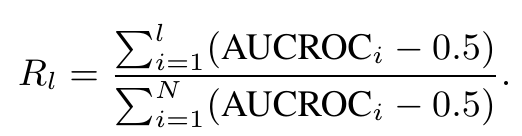
结果深层layer的相关性更高,达到0.8,而浅层layer相关性低

代码实现
假设的应用
Anchor-reweighting
Each β0 i is a learnable parameter, set uniquely for different attention heads and layers.
Attn weight直接乘上一个可学习权重,给重要的东西多关注一点,见Appendix G
代码实现:
1 | class AttentionAdapter(AttentionAdapterBase): |
Compress
还是利用ICL的特性,示例 + 正文
用标签位置的hidden state来代表整个示例(ICL中的示例概念)
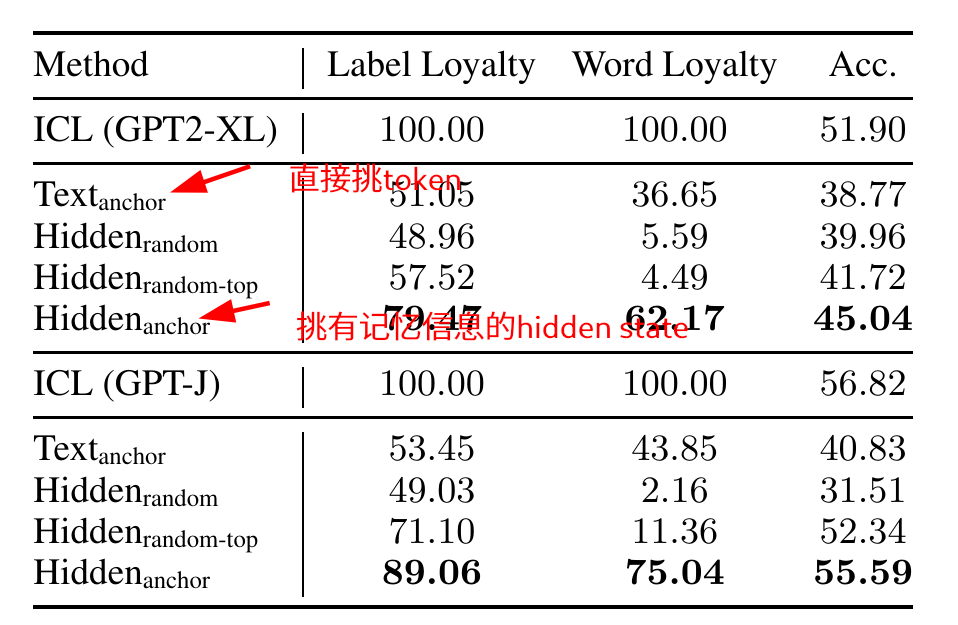
- Text_anchor直接取文本的标签 => 不行
- Hidden_anchor取标签对应的hidden state => 行
代码实现:只保留lable所在位置的kvcache。但如果不是ICL没有lable怎么办
1 | # 根据ICL的模板(示例 + 正文)可以提取到lable |