
cutlass cute实现flash attention
用cutlass cute实现flash attention
flash attention自顶向下(虽然我学cutlass是自底向上学的但是感觉快速上手应该自顶向下学)。因为有了cutlass cute用户就可以方便的实现一些功能了, 即一些cuda编程的范式:
- cuda程序范式: global mem -> share mem -> reg -> compute
- block tiling:
- aka 复用smem, gmem -> smem的拷贝
- thread tiling:
- aka 复用reg, smem -> reg的拷贝
- 合并访存, 向量访存:
- aka 向量指令, LDSM, ldmatrix指令
- warp divergent线程束分化
- aka warp负载均衡, 同理流水线气泡问题
- bank conflict冲突消解: swizzle
- aka 利用内存的多路通道
- double buffering
- aka 加载和计算的流水线
- …
- block tiling:
需要自底向上学的朋友推荐看reed哥的系列教程
flash attention速通
TODO: 简单描述一下flash attention的本质: flash attention three easy pieces
- online safe softmax
- 两个gemm的融合
- rescale的数学原理
自顶向下cute flash attention
在不考虑使用cutlass的情况下, 纯cuda应该怎么写高性能算子:
- 多维block tiling:
- 把数据从global memory拷贝到shared memory
- 复用smem中的数据, 减少访问gmem的此时
- 多维thread tiling
- 把数据从shared memory拷贝到global memory
- 复用寄存器中的数据
- 进一步优化
- 使用向量指令异步加载
- LDSM
- ldmatrix
- 合并访存
- bank conflict冲突消解
- 传算交叠流水线: 一边gmem -> smem拷贝一边做reg的gemm计算
而cutlass cute则把原本需要手写的thread协同工作的代码抽象封装好了, 如需要协同做拷贝时可以make_tiled_copy创建一个拷贝对象, 需要协同计算时可以用TiledMMA<T>创建mma(matrix multiply accumulate)对象来做计算。
只需要看懂mma布局就知道thread间如何协同的, 后面基础设施章节会介绍
Terms 名词解释
- 命名习惯:
tQgQ- 看到cute的变量名可能一头雾水, 所以有必要解释一下
- 如
auto tQgQ = gmem_thr_copy_QKV.partition_S(gQ(_, _, 0)),t(to)表示是给什么用的, 这里只是抽象了一层还是Q本身所以直接用tQ。g表示该变量的位置在global memory中 - 如
tSrQ,tSrK表示是给attention Score计算使用的, 寄存器(reg)中的Q, K - 如
tOrVt表示是给最终output用的, 寄存器中的转置过了的V
- MNK矩阵乘法表述法
- 两个矩阵相乘需要至少一个维度相同, K就表示这个相同的维度是多少
A[M, K] @ B[N, K]
- MMA(matrix multiply accumulate)
- 简单的说就是用于表示thread tiling的规模, 即一个thread block中用多少个thread怎么计算, cute会抽象成一个个mma对象
- MMA描述法: 描述底层执行
D = AB + C要使用的指令, 用户可以根据需要指定- 描述方法: DABC + MNK
- DABC: 描述了寄存器类型, 如
SM75_16x8x8_F32F16F16F32_TN中F32F16F16F32就是DABC描述。表示DABC寄存器分别是F32,F16,F16,F32 - MNK: 描述了矩阵乘法的规模, 如
SM75_16x8x8_F32F16F16F32_TN中16x8x8就表示D[M, N] = A[M, K] * B[N, K] + C[M, N]
- Tiled_MMA: 描述多个MMA_Atom如何协作来完成一个大任务
- AtomLayoutMNK: Tile内在MNK方向上重复几次Atom, 通过多线程重复
- ValueLayoutMNK: Atom内在MNK方向上重复几次计算, 单线程内重复计算
- BlockM
- Q的分块计算的粒度
- BlockN
- KV的分块计算的粒度
基础设施
- 查看MMA布局
使用这个mma布局打印脚本可以打印, 使用方法如下: 修改不同mma指令SM80_16x8x16_F32F16F16F32_TN来测试。
1 | { |

图片含义:T0, T1…表示thread,T0内V0, V1表示thread T0所负责的数据
- 打印tensor
直接使用cute提供的print_tensor, print_layout可以在命令行打印出tensor数据, 方便调试。e.g.
1 | // Convert a C pointer into cutlass Tensor |
使用local_tile打印一个tile(一个tensor切片)
1 | cute::print_tensor(A); |
attention计算的线程模型
单线程的attention计算belike: q[seqlen, headdim] @ k[seqlen, headdim].T @ v[seqlen, headdim]
而多线性的attention计算只需要从q的维度切分(想象成自回归场景下, 一次计算一个token的attention, 这里是并行的计算多个”单”query的attention),每个thread负责BlockM个token的single head attention计算。即
如果输入的形状为[bs, head, seqlen, headdim]则总线程数为bs x head x seqlen/BlockM, 每个thread计算[BlockM, headdim]的query attention计算。在bs x head维度和seqlen维度都并行。
对应到每个独立的thread block上也是同理, 开辟bs x head x seqlen/BlockM个独立的线程块进行多个token的并行计算。
1 | dim3 grid(ceil_div(params.seqlen, BlockM), params.bs * params.head, 1); |
TODO: 示意图
二维block tiling
flash attention 2的计算流程如下图所示, Q按inner loop顺序分别和K, V分开进行计算得到partial sum, 最后将partial sum累加得到和Q形状一样的输出。伪码描述为(先不用考虑online softmax和rescale的原理)
1 | flash_attention_2(): |
你可能发现outter loop和inner loop和流传甚广的经典的flash attention那张三角形的图不一样。这是因为那张图的flash attention 1时期的实现。
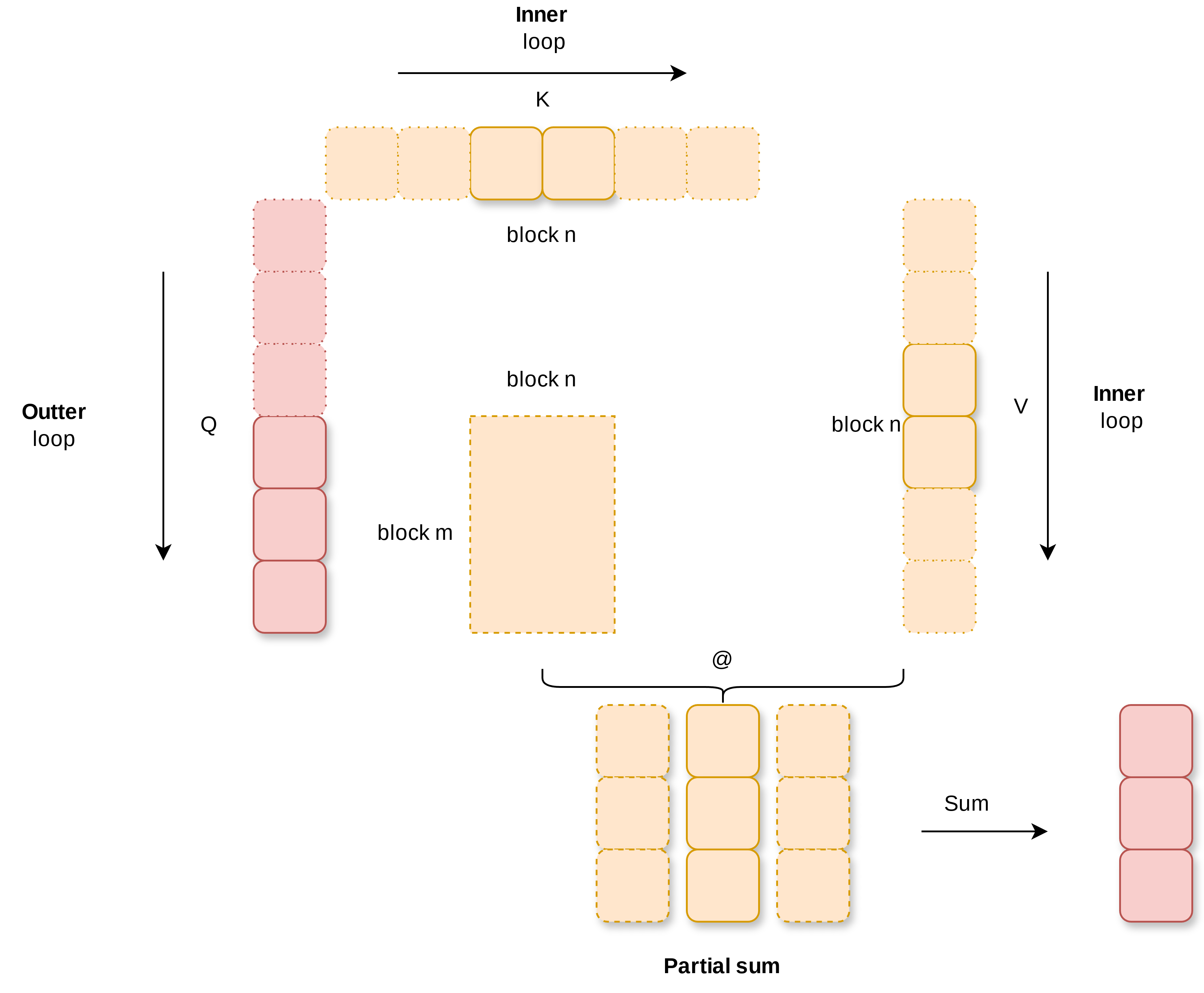
利用cute的api可以快速制造q, k, v分块:
- 用
make_tensor()把裸指针封装成tensor方便后续操作 - 使用
local_tile(tensor, tile, coord)从tensor中取出一组/一个分块 - 创建
Copy_Atom拷贝对象实现global memory到shared memory的数据拷贝, 简单易用的多维block tiling
首先使用make_tensorAPI可以把传入的裸指针转换成更方便使用的Tensor。这里把完整seqlen x dim的QKV对象创建了出来,方便后面使用cute的API做q_slice[i++]之类的操作。不用担心make_tensor会产生额外的开销, 因为它不会。
1 | // dim3 grid(ceil_div(params.seqlen, BlockM), params.bs * params.head, 1); |
根据block id加载thread block对应的qkv分块。local_tile(tensor, tile, coord)可以把tensor抽象成由多个tile组成的数组(可以多多维), 然后使用coord去索引取出需要的部分。这里取出了当前thread block负责的Q分块,并取出第一个kv分块做后续”传算交叠流水线”的prefill.
因为这里Q的shape是seqlen, kHeadDim, 所以拆分成多个[kBlockM, kHeadDim]的块后可索引的coord为[seqlen/kBlockM, kHeadDim/kHeadDim]。取出[m_block, _], 相当于python中的[m_block, :]这样的索引方式, 其中m_block索引维度的会被squeeze, 而_索引的维度会保留。所以最终的shape为(kBlockM, kHeadDim, num_tile_n=1)
1 | // 加载Q, K, V分块 |
将数据从global memory拷贝到shared memory来做多维的block tiling: 定义从global memory到share memory拷贝的对象, 这样可以减少用户直接使用gpu指令。具体拷贝对象怎么构造后续再说, 简单的说就是使用一个config来配置用什么方法拷贝(异步的, 向量的)。
1 | // Construct SMEM tensors. |
其中, gmem_thr_copy_QKV.partition_S()创建拷贝的源地址对象, gmem_thr_copy_QKV.partition_D()创建拷贝的目标地址对象。因为gQ我们在创建分块时第二个维度用满了, 所以make_coord(m_block, _)提取出来也只有一个元素, 直接用0索引掉。
1 | // tQgQ: tQ: 用于(t)表示/计算Q. gQ: 是global memory上的数据 |
然后使用API即可实现一个多维数据的拷贝。
1 | // NOTE: gmem_tiled_copy_QKV为cute抽象出来的拷贝对象Copy_Atom, 表示用一组thread来做拷贝 |
具体gmem_thr_copy_QKV拷贝对象的构造方法后面再说, 只需要传入一个异步拷贝的参数和规模布局即可用上向量指令做异步拷贝。
这是不是比手写gpu指令的block tiling各种拷贝简单多了:
二维thread tiling
本章节开始进入inner loop部分
1 | flash_attention_2(): |
整体流程如下
- pipeline prefill: load(q), load(k[0])
- pipeline start
- async_load(next(v)) && compute q @ k.T
- softmax(qk)
- async_load(next(k)) && compute qk @ v
- pipeline finish
- rescale
其中做gemm计算时都会从smem拷贝多维的数据到寄存器中做一个thread tiling。thread tiling可以复用已经拷贝到寄存器的数据,减少smem到reg拷贝的次数。如下图所示, 当gemm计算第0行时, BX0和A0X计算完成后, BX1可以直接利用已经在寄存器的A0X而不用再次做smem到reg的加载。

从gemm的角度出发看多维thread tiling的实现。使用cute::copy把smem中的数据tCsA拷贝到寄存器中tCrA后直接使用cute::gemm做多维thread tiling的gemm计算。具体thread tiling的布局通过可以通过打印mma查看。
1 | template<typename Tensor0, typename Tensor1, |
for循环前先做一次cute::copy是为了构造传算交叠(communication compute overlap)的流水线。即做smem->reg拷贝的同时做gemm。
回到cutlass flash attention的代码。使用cute提供的API构造gemm需要的寄存器对象。TODO: 具体SmemCopyAtom拷贝对象的构造方法后面再说, 只需要传入一个异步拷贝的参数和规模布局即可。
使用partition_fragment_A, partition_fragment_B, partition_fragment_C创建寄存器对象, 准备做thread tiling: 把数据从smem拷贝到reg, 并利用reg中的数据做矩阵乘法。
1 | // NOTE: 定义smem -> reg拷贝的dst |
inner loop部分代码如下。其中, 创建auto rAccScore = partition_fragment_C()来融合两个gemm: score = q@k.T的gemm和out = score @ v的gemm。
需要注意融合两个gemm的坑点, 因为要融合两个gemm, gemm-I的输出score = q@k.T要作为第二个gemm-II的输入out = score @ v, 所以gemm-I的输出C layout需要和gemm-II的输入A layout一致才能直接使用。通过打印mma指令发现SM80_16x8x16_F32F16F16F32_TN就符合这种要求。
ColfaxResearch的实现似乎不用考虑这点, 用rs_op_selector和ss_op_selector两个API就把MMA配置好了。如果有人知道是怎么回事pls let me know.
1 | /* |
伪码和代码的对应情况如下:
1 | # inner loop |
传算交叠流水线
- 异步拷贝
创建gmem到smem的拷贝对象时使用SM80_CP_ASYNC_CACHEGLOBAL指令来创建异步拷贝的Copy atom对象。
1 | using Gmem_copy_struct = std::conditional_t< |
- 流水线
伪码描述如下, 计算q@k时可以加载v, 计算qk@v时加载下一次迭代需要的k。目前只是用double buffering的方式预取1个kv. 如果每次预取多个kv还需要考虑smem大小对性能的影响。
1 | # inner loop |
在cutlass cute中使用也很简单, 构造好异步拷贝对象后发起异步拷贝即可。
1 | // gemm的同时异步加载V |
其他细节
- causal模式的提前返回
- block间早退
- block内mask: thread在mma中的定位
- 结果拷贝回global memory返回
- 同样利用smem, 先从reg拷贝到smem再从smem拷贝到gmem
- 这样可以用更大的位宽
- online safe softmax
- pybind和模板展开
- 官方实现用了很多模板,本质就是1. 枚举所有可能的分块策略 2. 每个config写一个文件加速编译 3. 每个模板写个文件微调最佳config
- python中接入cpp代码可以看这个仓库
后面再展开补充,感兴趣的朋友可以先看源码注释。
其他优化
- bank conflict重复避免
- swizzle
- cutlass cute封装好了用swizzle解决bank conflict, 在创建拷贝对象时使用即可
- 转置优化
- 拷贝时直接拷贝到转换后的目标地址, 从而不必开辟新的空间
- 创建拷贝对象时, 配置布局时把dst的布局转置掉即可
- 高性能的reduce实现
- 优化线程束分化问题(warp divergent)
TODO: 细节展开
稍微一点自底向上
深入的自底向上可以看reed哥的系列教程
TODO: 挑选几个重要的
主要坑点
- 两个gemm的融合的layout问题: gemm-I, gemm-II
- 输入输出的布局比较讲究: gemm-I的输出C layout要和gemm-II的输入A layout一致