
手把手实现Ring Attention
手把手实现Ring Attention
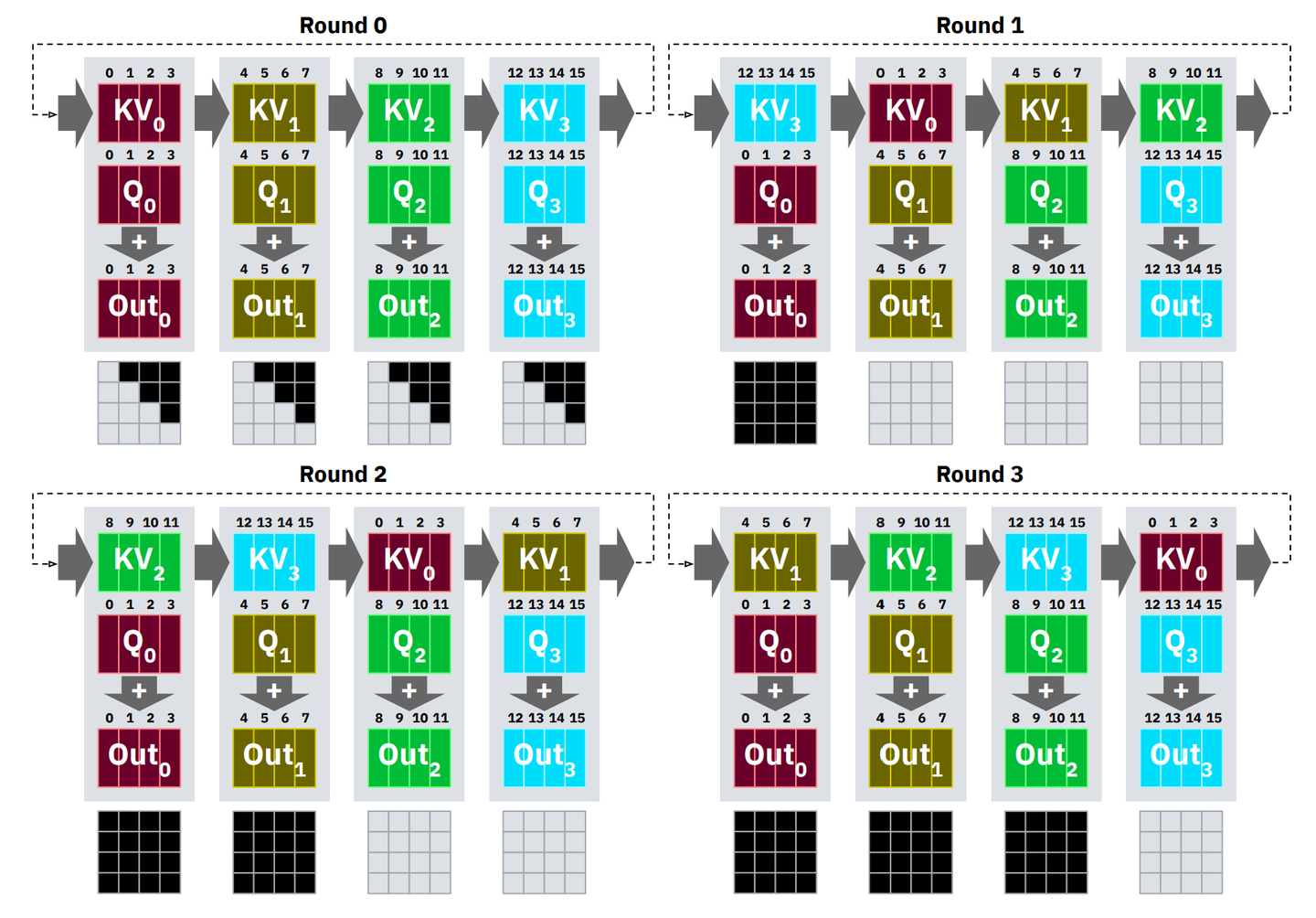
官方ring attention是jax实现的,这里用pytorch实现一个ring attention的学习版本。
是ring attention是attention机制的分布式版本。分布式的持有QKV分块从而降低单机的显存消耗。
主要流程:
- 数据并行模拟: 不想折腾DDP, 使用一些技巧来模拟
- p2p通信
- 给ring attention定制flash attention
模拟DDP环境
- 使用全局数据模拟DDP, 让每个rank看到不同的数据片段即可
- e.g.
real_q = global_q[:,:, rank * seq_per_rank: (rank + 1) * seq_per_rank, :]
- e.g.
- 每个rank使用相同的随机数种子生成随机数, 以确保数据一致性和正确性验证
简单的p2p通信
使用pytorch的p2p操作
1 | # 接收前一个rank的kv分块, 向下一个rank发送kv分块 |
ring attention
flash attention算法伪码描述:
1 | flash_attention(): |
可以看到flash attention内执行了rescale, 因此不能直接使用flash attention来计算ring attention的qkv分块。因此我们可以仿照flash attention重写, 这样我们就可以在p2p的kv send recv结束后再做rescale。
仿照flash attention就能写出ring attention的伪代码:
1 | ring_attention(): |